
Les moteurs de recherche tels que Google ont un problème. On l’appelle «Duplicate content». Duplicate Content signifie qu’un contenu similaire est affiché sur plusieurs emplacements (URL) sur le Web. Cet article est destiné à comprendre les différentes causes du Duplicate Content et à trouver la solution pour chacun d’eux.
Il est possible de comparer le contenu en double à un carrefour. Les panneaux indiquent deux directions différentes pour la même destination finale: quelle route devons nous prendre ? Et maintenant, afin de rendre les choses encore plus désagréable, la destination finale est également différente. En tant que lecteur, cela ne vous gênera certainement pas. Dans tous les cas, vous aurez accès au contenu pour lequel vous êtes venu. Un moteur de recherche, quant-à-lui, doit choisir lequel afficher dans les résultats.
1 Causes du Duplicate Content
Il y a des dizaines de raisons pouvant causer le Duplicate Content. La plupart d’entre eux sont techniques: il n’est pas très rare qu’une personne décide de mettre le même contenu dans deux endroits différents sans distinguer la source originelle. Les raisons techniques sont cependant abondantes. Cela se produit surtout parce que les développeurs ne pensent pas en tant que navigateur ou utilisateur, sans parler du fait qu’il est très rare que l’on comprenne le langage des moteurs de recherche.
1.1 Incompréhension du concept d’URL
Est-ce que ce développeur est devenu fou? Non, il parle simplement une langue différente. Vous voyez que tout le site Web est probablement alimenté par un système de base de données. Dans cette base de données, il n’y a qu’un article, le logiciel du site Web permet de retrouver ce même article dans la base de données via plusieurs URL. C’est parce que dans les yeux du développeur, l’identifiant unique pour cet article est l’ID que cet article a dans la base de données, et non l’URL. Pour le moteur de recherche cependant, l’URL est l’identifiant unique d’un contenu. Si vous expliquez cela à un développeur, il va commencer à résoudre le problème. Et après avoir lu cet article, vous pourrez même lui fournir une solution tout de suite.
1.2 ID de session
Vous voulez souvent garder une trace de vos visiteurs, et permettre, par exemple, de stocker des articles qu’ils souhaitent acheter dans un panier. Pour ce faire, vous devez leur donner une «session». Une session est essentiellement une brève histoire de ce que le visiteur a fait sur votre site, et peut contenir des choses comme les articles dans leur panier. Pour maintenir cette session en tant que clic du visiteur d’une page à l’autre, l’identificateur unique de cette session, l’ID de la session appelée, doit être stocké quelque part. La solution la plus commune est de faire cela avec des cookies. Toutefois, les moteurs de recherche ne stockent généralement pas les cookies.
À ce moment-là, certains systèmes retournent à l’utilisation des ID de session dans l’URL. Cela signifie que chaque lien interne sur le site Web reçoit cette ID de session ajoutée à l’URL, et parce que cet ID de session est unique à cette session, il crée une nouvelle URL et donc duplique le contenu.
1.3 Paramètres URL utilisés pour le suivi et le tri
Une autre cause du contenu en double est l’utilisation de paramètres d’URL qui ne modifient pas le contenu d’une page, par exemple dans les liens de suivi. Vous voyez, https://www.example.com/keyword-x/et https://www.example.com/keyword-x/?source=rssne sont pas la même URL pour un moteur de recherche. Ce dernier pourrait vous permettre de suivre les sources de provenance, tout en ayant un effet secondaire très indésirable!
Cela ne s’applique pas seulement aux paramètres de suivi, bien sûr, il correspond à chaque paramètre que vous pouvez ajouter à une URL qui ne modifie pas le contenu essentiel. Que ce paramètre soit pour «changer le tri sur un ensemble de produits» ou pour «afficher une autre barre latérale»: ils génèrent tous du contenu en double.
La plupart des causes du « duplicate content » sont de votre faute, ou du moins, de la « faute » de votre site internet. Parfois aussi, d’autres sites internet utilisent votre contenu, avec ou sans votre consentement. Ils ne se lient pas toujours à votre article original et, par conséquent, le moteur de recherche ne l’obtient pas et doit faire face à une autre version du même article.
1.5 Ordre des paramètres
Une autre cause commune est qu’un CMS n’utilise pas d’URL agréables et propres, mais plutôt des URL /?id=1&cat=2, où l’ID se réfère à l’article et le cat se réfère à la catégorie. L’URL /?cat=2&id=1donnera exactement les mêmes résultats dans la plupart des systèmes de sites Web, mais ils sont en fait complètement différents pour un moteur de recherche.
1.6 Pagination de commentaires
Dans mon bien-aimé WordPress, mais aussi dans d’autres systèmes, il existe une option pour la pagination de vos commentaires. Cela entraîne la duplication du contenu dans l’URL de l’article et l’URL de l’article + /comment-page-1/, /comment-page-2/, etc.
1.7 Nom de domaine avec WWW ou sans WWW
L’un des plus ancien, mais il arrive encore que les moteurs de recherche se trompent: Le Duplicate Content WWW ou sans WWW, lorsque les deux versions de votre site sont accessibles. Une situation moins commune, mais celle que j’ai déjà vu: http contre https contenu en double, où le même contenu est diffusé sur les deux. C’est pourquoi, bon nombre d’hébergeurs Web redirige WWW sur le nom de domaine nu (sans www).
2 Solution conceptuelle: URL canonique
Comme déterminé ci-dessus, le fait que plusieurs URL conduisent au même contenu est un problème, mais il peut être résolu. Une personne travaillant sur une publication sera normalement capable de vous informer assez facilement de l’URL «correcte» d’un certain article. Ce qui est drôle cependant, parfois, lorsque vous demandez à trois personnes dans la même entreprise, ils donneront trois réponses différentes …
C’est un problème qui doit être résolu dans ces cas, car en fin de compte, il ne peut y avoir qu’un (URL). Cette URL «correcte» pour un contenu a été baptisée l’ URL canonique par les moteurs de recherche.
3. Identification des problèmes de Duplicate Content
Vous ne savez peut-être pas si vous avez un problème de Duplicate Content sur votre site ou avec votre contenu. Permettez-moi de vous donner quelques méthodes pour savoir si vous en avez.
3.1 Outils Google Webmasters Tools
Google Webmaster Tools est un excellent outil pour identifier le contenu en double. Si vous allez dans Google Webmaster Tools pour votre site, cochez la case Rechercher apparence »HTML Improvements , et vous verrez ceci:
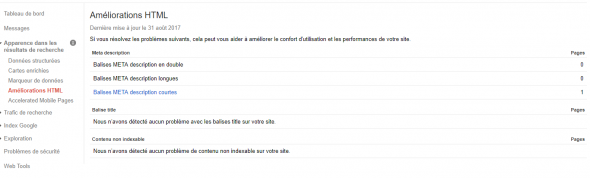
Si les pages ont des titres en double ou des descriptions en double, ce n’est pas une bonne chose. En cliquant dessus, vous verrez apparaître les URL qui ont des titres ou des descriptions en double et vous aideront à identifier le problème. La question est que si vous avez un article comme celui sur « keyword-x », les titres peuvent être différents. Google ne les définira pas comme des titres en double.
3.2 Rechercher des titres ou des extraits
Il existe plusieurs opérateurs de recherche qui sont très utiles pour des cas comme ceux-ci. Si vous souhaitez trouver toutes les URL sur votre site contenant l’article de votre mot – clé X , vous devez taper la phrase de recherche suivante dans Google:
- site: exemple.com intitle: « mot-clé »
Google vous montrera toutes les pages sur exemple.com qui contiennent ce mot-clé.
4 Solutions pratiques pour le contenu en double
Une fois que vous avez décidé quelle URL est l’URL canonique pour votre contenu, vous devez commencer un processus de canonisation. Cela signifie que nous devons faire savoir au moteur de recherche quelle est la version canonique d’une page. Il existe quatre méthodes de résolution du problème, par ordre de préférence:
- Ne pas créer de contenu en double
- Redirection du contenu en double vers l’URL canonique
- Ajout d’un élément de lien canonique sur la page en double
- Ajout d’un lien HTML de la page en double vers la page canonique
4.1 Eviter le Duplicate Content
Certaines des causes ci-dessus pour le contenu en double ont des corrections très simples:
- Les ID de session dans vos URL? Ceux-ci peuvent souvent être désactivés dans les paramètres de votre système.
- Vous avez des pages imprimables en double? Vous devriez simplement créer une feuille de style pour l’impression
- Utilisation de la pagination de commentaires sur WordPress? Désactivez simplement cette fonction
- Paramètres dans un ordre différent? Dites à votre programmeur de créer un script pour que les paramètres se mettent toujours dans le même ordre.
- Suivi des problèmes de liens? Dans la plupart des cas, vous pouvez utiliser le suivi de la campagne basée sur les balises hash au lieu du suivi basé sur les paramètres.
- WWW et sans WWW? Choisissez en un et redirigez le second vers le premier. Vous pouvez également définir une préférence dans Google Webmaster Tools.
Si vous ne pouvez pas résoudre votre problème facilement, il est tout de même nécessaire d’essayer de le faire. L’objectif principal est d’éviter le Duplicate Content sur votre site internet. C’est de loin, l’une des meilleures solutions au problème.
4.2 Redirection du contenu en double
Dans certains cas, il est impossible d’empêcher complètement le système que vous utilisez de créer des URL incorrectes pour le contenu, mais parfois il est possible de les rediriger. Si cela n’est pas logique pour vous, cela reste néanmoins nécessaire.
5 Conclusion: Le Duplicate Content peut être supprimé
Le contenu en double se produit partout. Je n’ai pas encore rencontré un site de plus de 1 000 pages qui n’a pas eu au moins un petit problème de contenu en double. Cela est quelque chose que vous devez surveiller attentivement. Il est toutefois fixable, et les récompenses peuvent être abondantes. Votre contenu de qualité pourrait monter dans le classement en se débarrassant simplement du contenu en double sur votre site !









